왜 이 생각을 못 했을까?
많은 사람들이 "왜 블로그에 글을 올렸는데 인덱싱이 안 되지?" 하고 답답해한다. 나도 그랬다. 나는 구글이 내 블로그를 외면하고 있고, 나는 그냥 웹이라는 광활한 공간에서 미치도록 외로운 싸움을 하고 있는 거라 느꼈다.
그러다가 공부를 하다 보니 크롤링이라는 것도 결국 구글봇이 내 웹사이트로부터 페이지를 달라고 요청하는 거고, 그 요청은 내 서버에 로그라는 형태로 기록이 남으며, 그 로그에는 요청 일시부터 그 요청에 내 웹사이트가 어떻게 응답했는지까지 다 나온다는 사실을 알게 되었다.
바로 ㄱㄱ.
구글봇이 내 웹사이트에 오긴 했나 확인하는 방법
나는 운영체제로는 우분투(Ubuntu)를, 웹 서버로는 Nginx(엔진엑스)를 사용 중이다. 엔진엑스 말고 유명한 웹 서버로는 Apache(아파치), Caddy(캐디) 등이 있다.
서버 터미널에서 다음 명령어를 입력해서 구글봇이 내 웹 서버에 요청한 기록을 볼 수 있었다:
sudo grep -i "Googlebot" /var/log/nginx/access.log
그러면 로그가 쫙 뜨는데, 읽기 힘드니까 다 긁어서 제미나이에게 정리해 달라고 하면...
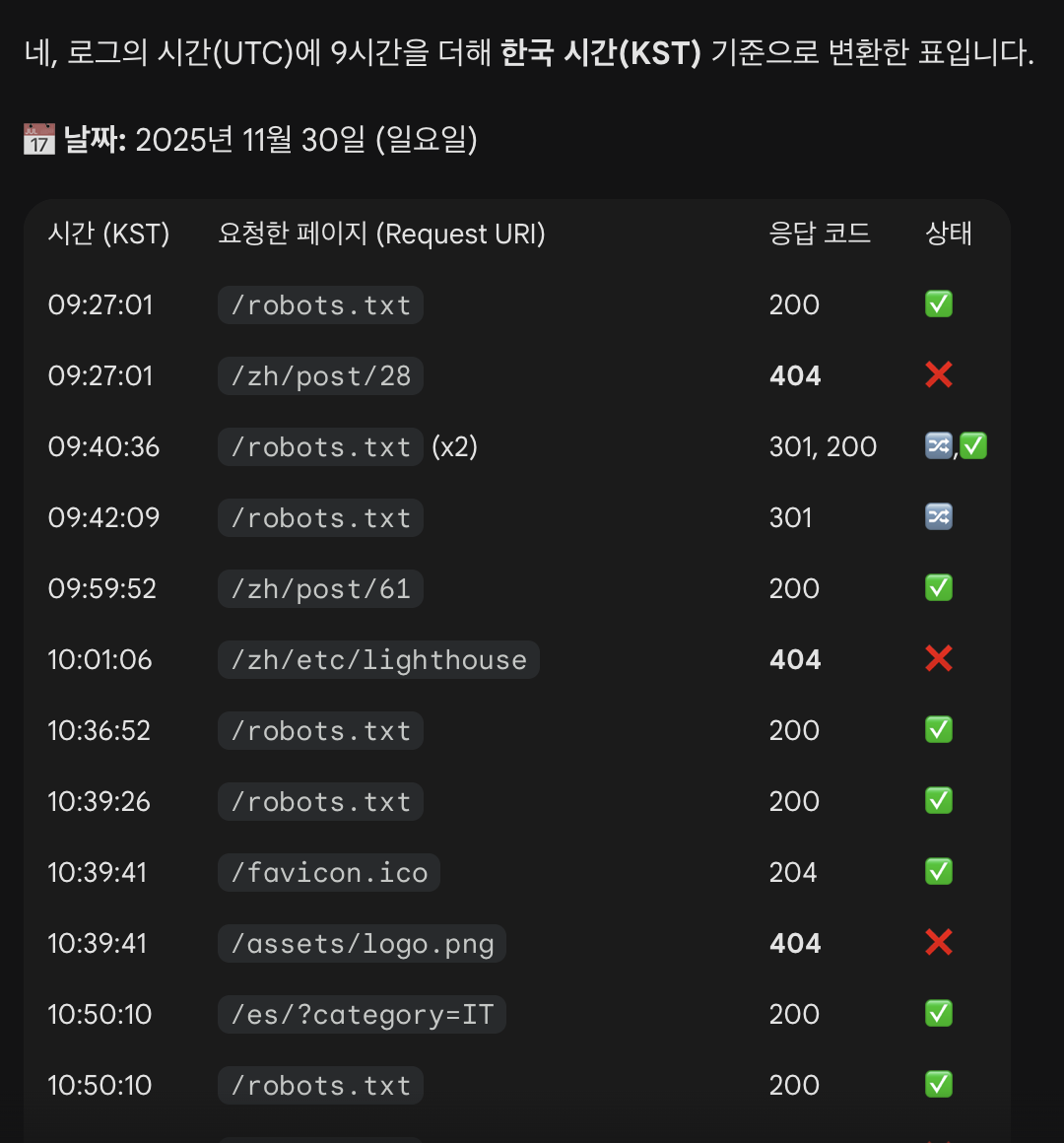 구글봇의 access 로그를 Gemini에게 요약 요청한 화면
구글봇의 access 로그를 Gemini에게 요약 요청한 화면
나는 마냥 내 웹사이트에 구글봇이 접근 자체를 안 하는 중이라고 생각했었는데, 구글봇은 늘, 꾸준히, 심지어는 내가 로그 기록을 조회하기 직전까지도 계속 들락날락하고 있었다.
구글봇이 수시로 확인하던 페이지들
robots.txt
가장 많이 요청한 페이지는 robots.txt였다. 이건 어떤 페이지를 수집하면 안 되는지를 기록한 것이기 때문에, 수시로 확인한다고 들었다.
예전에 올린 글들과 리소스들
그 다음으로 많이 요청한 건 예전에 이미 수집했던 웹페이지들이었다. 그 중 상당수는 현재 지워진 상태이기 때문에, 내 서버는 404를 반환했다. 이미 수집된 페이지들은 구글봇이 이미 그 존재를 알고 있기 때문에, 그걸 토대로 재요청을 하는 구조인 것 같다.
최신 글들
그렇다면 구글봇에게 아직 그 존재를 알리지 못한 최신 글들은...? 어제의 로그를 다음의 명령어로 조회해 보면,
sudo grep -i "Googlebot" /var/log/nginx/access.log.1이런 기록을 볼 수 있었는데,
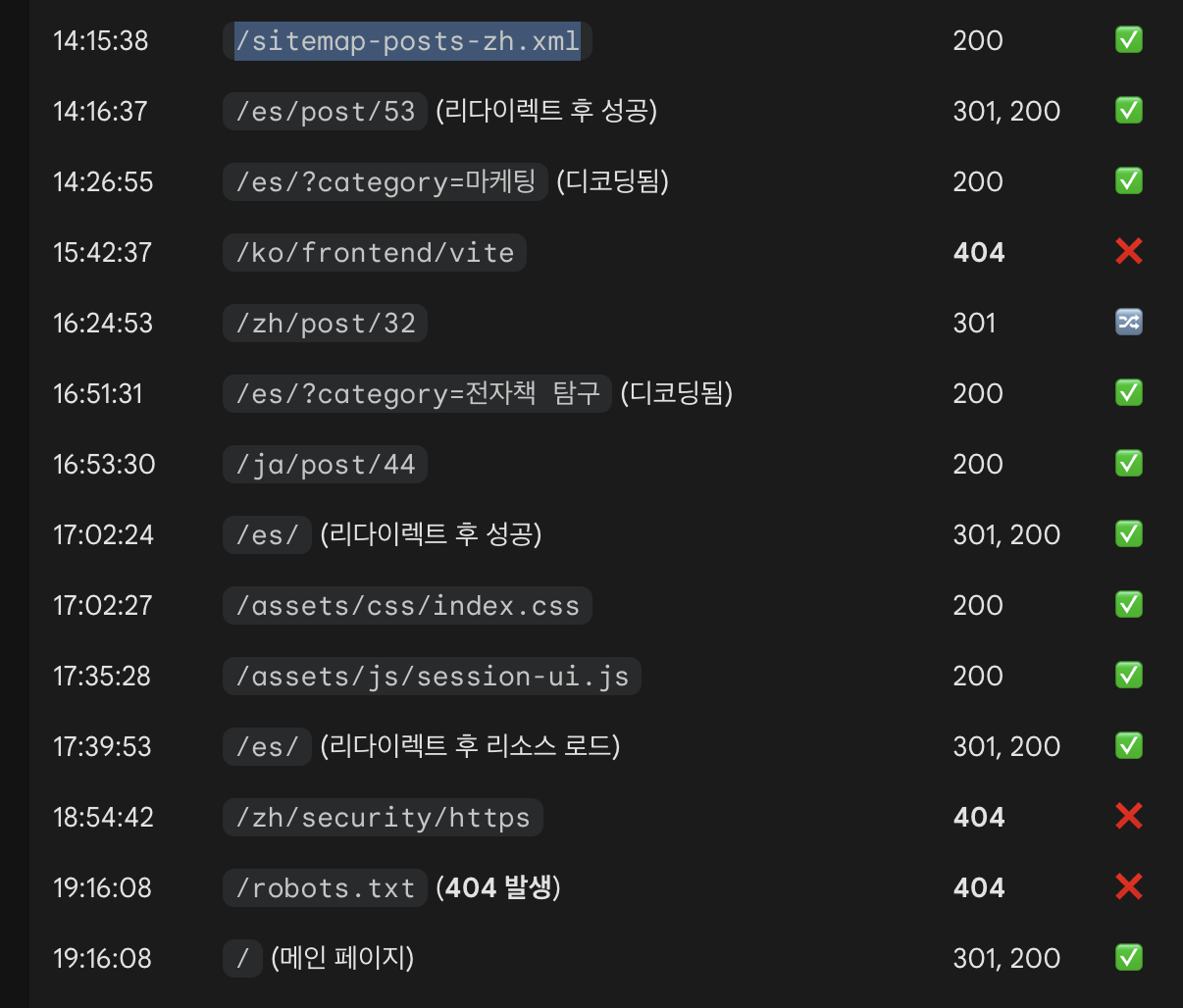 전날의 access.log에서 구글봇이 사이트맵 XML을 요청한 로그
전날의 access.log에서 구글봇이 사이트맵 XML을 요청한 로그
내 사이트맵에 있던, 특정 언어의 포스트 리스트를 담아 놓은 xml 파일을 요청한 기록이 있었다!
그러니까, 사이트맵이라는 걸 등록했다고 해서 "항상 참고"하는 것은 아니지만, 저렇게 드문드문 사이트맵을 통해 최신 글의 존재 여부를 확인하고 있었다.
실제로 최신 글들은 "오래된 순서부터 차례대로, 꼼꼼하게" 크롤링되는 것이 아니라, 저렇게 "우연히" 얻어 걸린 어떤 하나의 링크부터 시작해서 야금야금 크롤링이 퍼져나가는 방식이었다.
나는 평소에 글을 6개국어로 번역해서 올리는데, 최신 글들 중 특정 글들의 특정 언어만 일단은 크롤링을 한 상태였고, 아마 다른 글들도 차츰차츰 크롤링을 할 것 같다. 일단 크롤링이 되면, 그 문서를 분석해서 특별한 문제가 없는 한 인덱싱을 할 거고, 그러고 나면 검색에 내 글이 잡히게 될 것이다.
이론적으로 이 내용을 모르던 건 아닌데 막상 두 눈으로 보니까 엄청 신나네. 이런 거구나...