¿Cómo no se me ocurrió antes?
Mucha gente se pregunta frustrada: “¿Por qué no se indexa mi nueva entrada del blog?”. Yo era igual. Sentía que Google ignoraba por completo mi blog y que estaba librando una batalla solitaria en medio del vasto desierto del Internet.
Pero al estudiar un poco, descubrí que el crawling no es más que Googlebot enviando una solicitud para obtener páginas de mi sitio, y esas solicitudes se guardan en el servidor como logs. Los logs contienen todo: la fecha y hora de la solicitud y cómo mi servidor respondió.
Pues bien, vamos allá.
Cómo comprobar si Googlebot visitó mi sitio
Uso Ubuntu como sistema operativo y Nginx como servidor web. Otros servidores conocidos son Apache y Caddy.
Para ver las solicitudes de Googlebot, ejecuté este comando en el terminal del servidor:
sudo grep -i "Googlebot" /var/log/nginx/access.log
Aparece una enorme cantidad de registros, así que los copié y se los pedí a Gemini para que los resumiera...
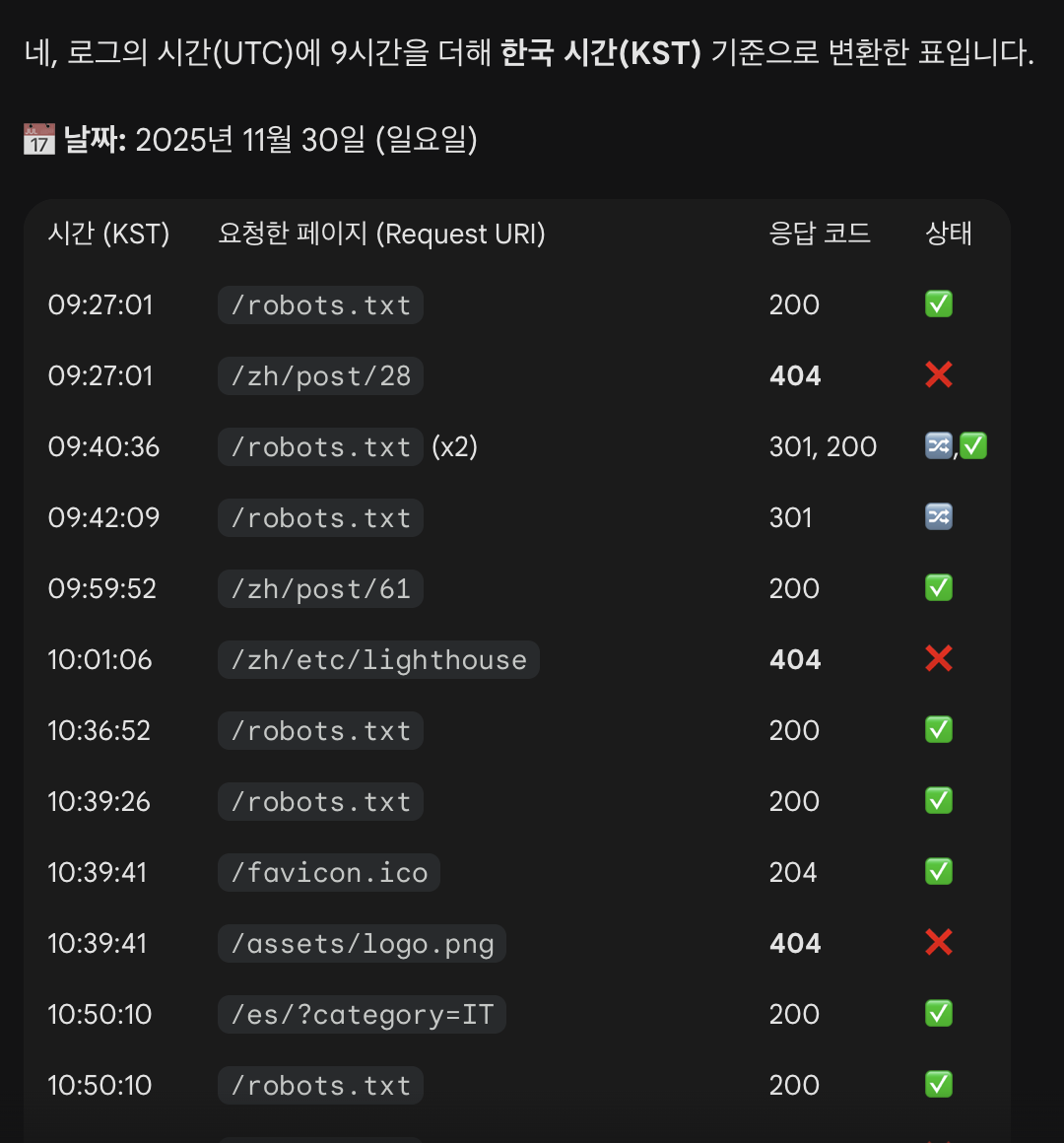 Resumen de los registros de acceso de Googlebot generado por Gemini
Resumen de los registros de acceso de Googlebot generado por Gemini
Yo pensaba que Googlebot nunca venía. Pero en realidad venía siempre, continuamente, incluso justo antes de que yo mirara los logs. Googlebot estaba entrando y saliendo sin parar.
Las páginas que Googlebot revisa con frecuencia
robots.txt
La página más solicitada fue robots.txt. Como indica qué páginas no deben ser rastreadas, es normal que Googlebot la revise constantemente.
Publicaciones y recursos antiguos
La segunda categoría más frecuente fueron páginas previamente indexadas. Muchas ya no existen, así que mi servidor devolvía 404. Googlebot vuelve a estas URLs porque ya las conoce de antes.
Publicaciones recientes
¿Y qué pasa con las publicaciones nuevas que Googlebot aún no conoce? Al revisar el log de ayer con este comando:
sudo grep -i "Googlebot" /var/log/nginx/access.log.1Aparecen registros como estos:
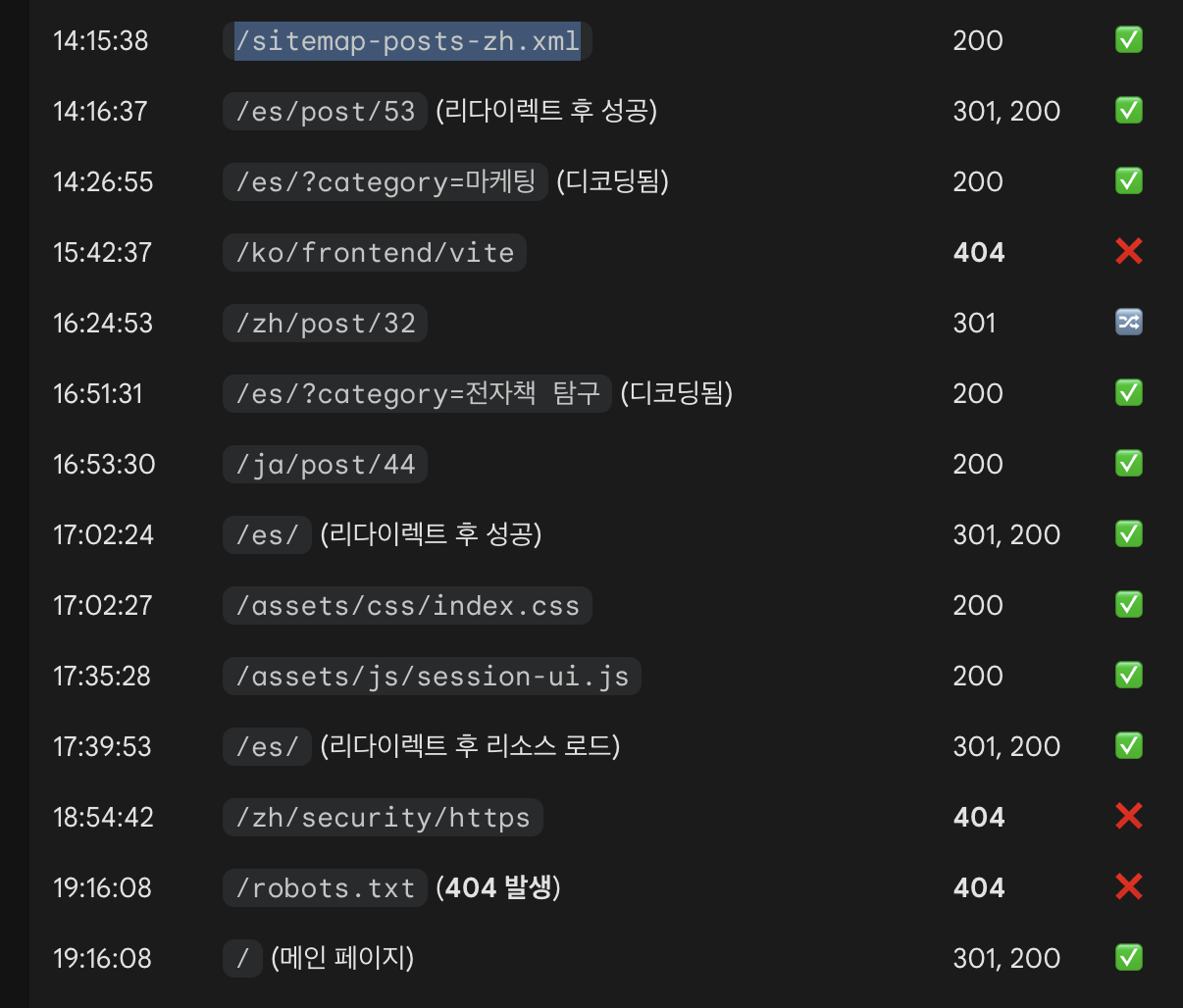 Registro donde Googlebot solicita un archivo XML del sitemap
Registro donde Googlebot solicita un archivo XML del sitemap
Googlebot solicitó un archivo XML de mi sitemap, el que contiene la lista de artículos para un idioma específico.
Esto significa que, aunque Google no consulta el sitemap “todo el tiempo”, sí lo usa ocasionalmente para comprobar si hay contenido nuevo.
En la práctica, las publicaciones recientes no se rastrean “ordenadas y meticulosamente de más antiguas a más nuevas”. Googlebot empieza desde algún enlace que encontró por casualidad y desde ahí se va expandiendo poco a poco.
Normalmente publico mis entradas en seis idiomas, y entre mis artículos recientes Googlebot solo había rastreado ciertas versiones de ciertos idiomas. Probablemente rastree el resto poco a poco. Una vez rastreado un artículo y analizado sin problemas, será indexado y aparecerá en los resultados de búsqueda.
Todo esto ya lo sabía “en teoría”, pero verlo con mis propios ojos en los logs fue muy emocionante. Así que… así es como funciona realmente.