Comment n’y ai-je pas pensé plus tôt ?
Beaucoup de gens se demandent, frustrés : « Pourquoi mon nouvel article n’est-il pas indexé ? » J’étais pareil. J’avais l’impression que Google ignorait totalement mon blog, et que je menais un combat désespérément solitaire dans l’immensité du web.
Mais en étudiant un peu, j’ai réalisé que le crawl, au fond, c’est simplement Googlebot qui envoie une requête pour récupérer des pages sur mon site. Et ces requêtes sont toutes enregistrées sous forme de logs sur mon serveur. Ces logs contiennent tout : la date et l’heure de la requête, ainsi que la façon dont mon site a répondu.
Allez, c’est parti.
Comment vérifier si Googlebot est venu sur mon site
J’utilise Ubuntu comme système d’exploitation et Nginx comme serveur web. Parmi les autres serveurs populaires, on trouve Apache et Caddy.
Pour voir les requêtes de Googlebot, j’ai exécuté la commande suivante dans le terminal :
sudo grep -i "Googlebot" /var/log/nginx/access.log
Une énorme liste de logs apparaît alors. Comme c’est difficile à lire, j’ai tout copié et demandé à Gemini d’en faire un résumé…
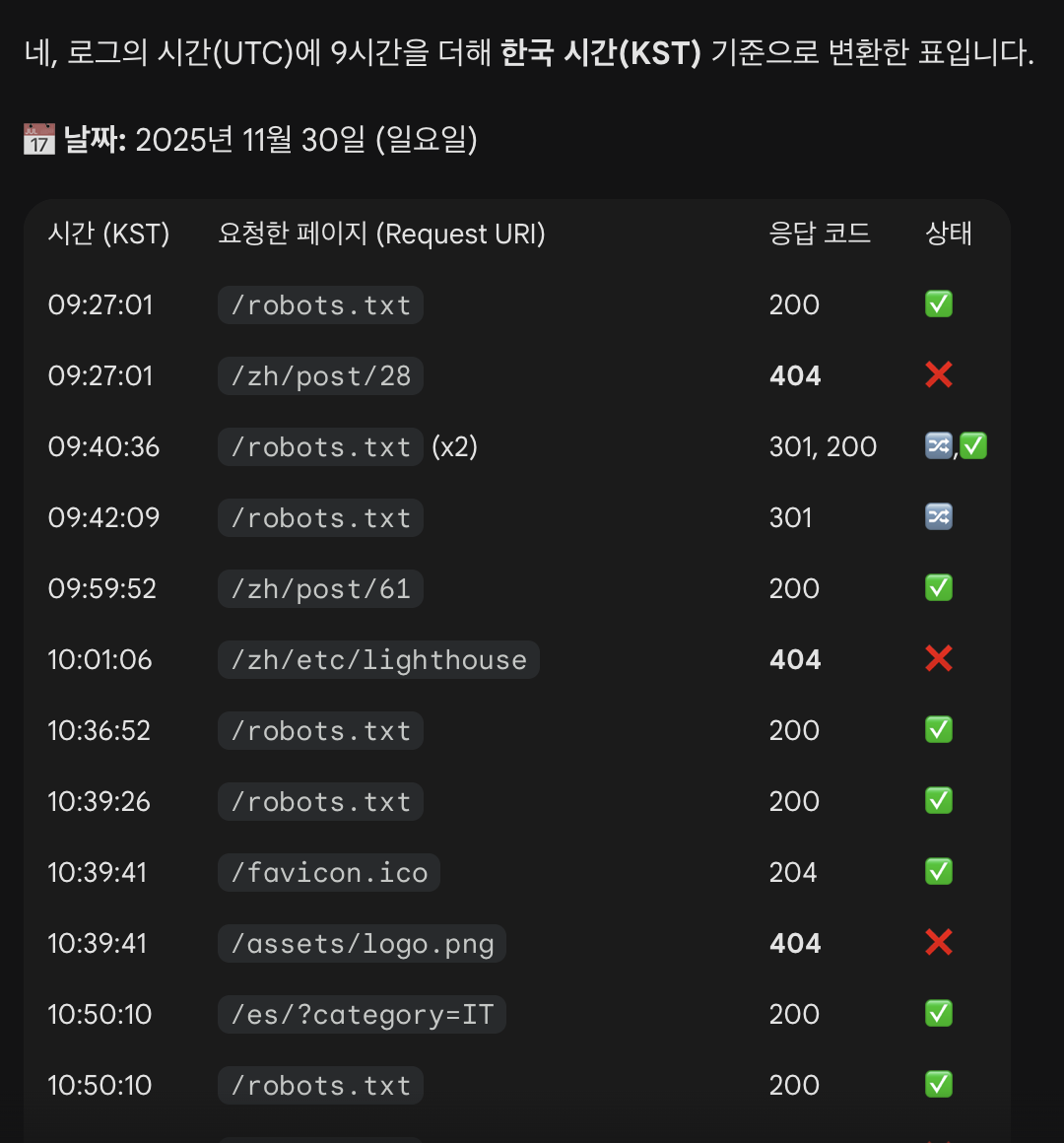 Résumé des logs d’accès de Googlebot généré par Gemini
Résumé des logs d’accès de Googlebot généré par Gemini
Je pensais vraiment que Googlebot ne visitait jamais mon site. Mais en réalité, il venait tout le temps, régulièrement, même juste avant que je consulte les logs. Googlebot allait et venait en continu.
Les pages que Googlebot consulte régulièrement
robots.txt
La page la plus demandée était robots.txt. C’est normal : c’est le fichier qui indique quelles pages ne doivent pas être collectées. Il est vérifié en permanence.
Les anciens articles et ressources
Ensuite venaient les pages déjà indexées auparavant. Beaucoup n’existent plus aujourd’hui, donc mon serveur renvoyait des 404. Comme Googlebot connaît déjà ces URL, il les reteste régulièrement.
Les articles récents
Et qu’en est-il des articles récents, ceux dont Googlebot ignore encore l’existence ? En regardant les logs d’hier avec cette commande :
sudo grep -i "Googlebot" /var/log/nginx/access.log.1On tombe sur des lignes comme celles-ci :
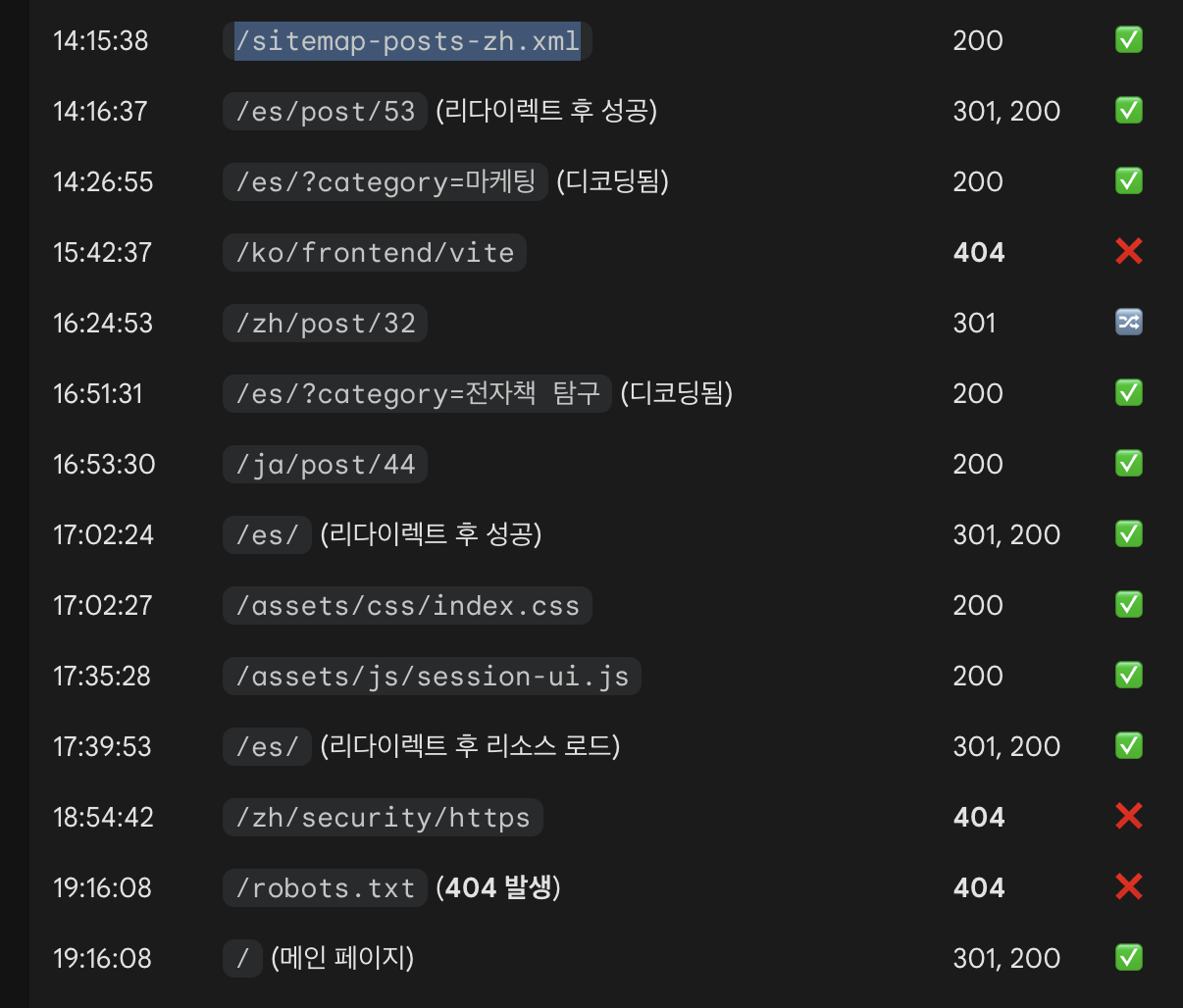 Googlebot consultant un fichier XML du sitemap dans access.log.1
Googlebot consultant un fichier XML du sitemap dans access.log.1
Googlebot avait demandé un fichier XML de mon sitemap, celui qui contient la liste des articles dans une langue spécifique.
Cela signifie que même si Google ne consulte pas le sitemap constamment, il l’utilise de temps en temps pour vérifier la présence de nouveaux contenus.
Dans la pratique, les articles récents ne sont pas crawlés « dans l’ordre, du plus ancien au plus récent ». Le crawl s’étend plutôt petit à petit à partir d’un lien que Googlebot découvre par hasard.
Je publie généralement mes articles en six langues, et parmi mes derniers contenus, Googlebot n’avait pour l’instant crawlé que certaines langues de certains articles. Il finira probablement par parcourir le reste progressivement. Une fois qu’un article est crawlé et analysé, il sera indexé — sauf problème particulier — et pourra alors apparaître dans les résultats de recherche.
Je connaissais tout ça « en théorie », mais le voir de mes propres yeux m’a vraiment excité. Ah… donc c’est comme ça que ça marche.