Why didn’t I think of this sooner?
Many people get frustrated wondering, “Why isn’t my new blog post getting indexed?” I was the same. I felt like Google was ignoring my blog entirely, and that I was just fighting an impossibly lonely battle in the vast desert of the web.
Then, while studying, I realized that crawling simply means that Googlebot is sending a request to fetch pages from my site, and those requests are saved on my server as logs. Those logs contain everything—from the timestamp of the request to how my server responded to it.
Alright, let’s go.
How to Check If Googlebot Has Visited My Website
I use Ubuntu as my operating system and Nginx as my web server. Other well-known web servers include Apache and Caddy.
To check Googlebot’s requests to my server, I ran this command in the terminal:
sudo grep -i "Googlebot" /var/log/nginx/access.log
It prints out tons of logs, and since they’re hard to read, I copied everything and asked Gemini to summarize it...
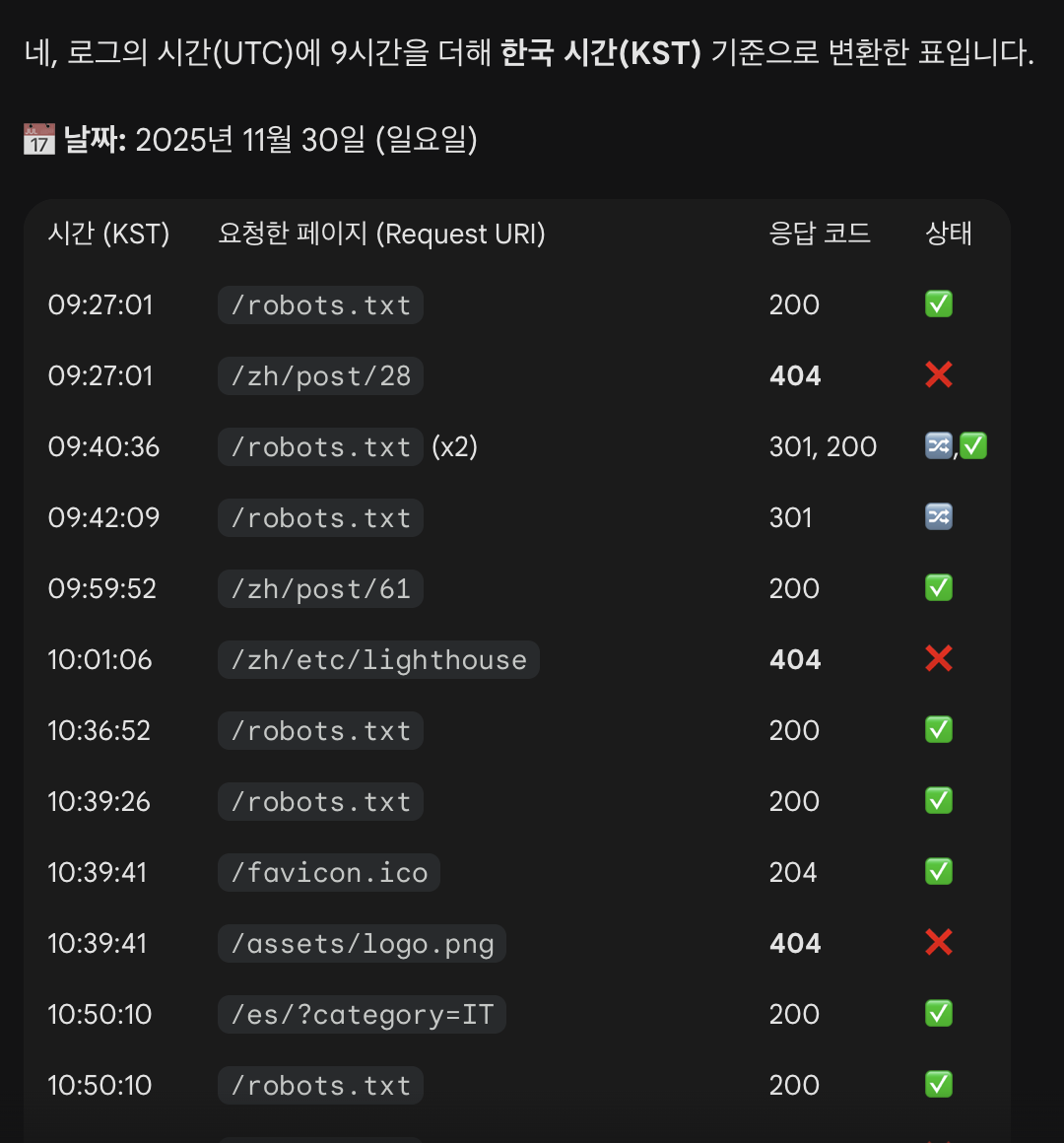 A summary of Googlebot access logs generated by Gemini
A summary of Googlebot access logs generated by Gemini
I honestly thought Googlebot wasn’t visiting my site at all, but it turns out it was coming consistently—constantly—even right before I checked the log. Googlebot was coming and going nonstop.
Pages Googlebot Frequently Checks
robots.txt
The most frequently requested page was robots.txt. This file tells crawlers which pages they shouldn’t collect, so it’s checked very regularly.
Older Posts and Resources
The second most common requests were for previously indexed pages. Many of these pages no longer exist now, so my server returned 404. Since Googlebot already knows these URLs exist, it keeps trying them again from time to time.
Recent Posts
So what about the recent posts whose existence Googlebot doesn’t yet know about? If you check yesterday’s logs with this command,
sudo grep -i "Googlebot" /var/log/nginx/access.log.1You can see logs like this:
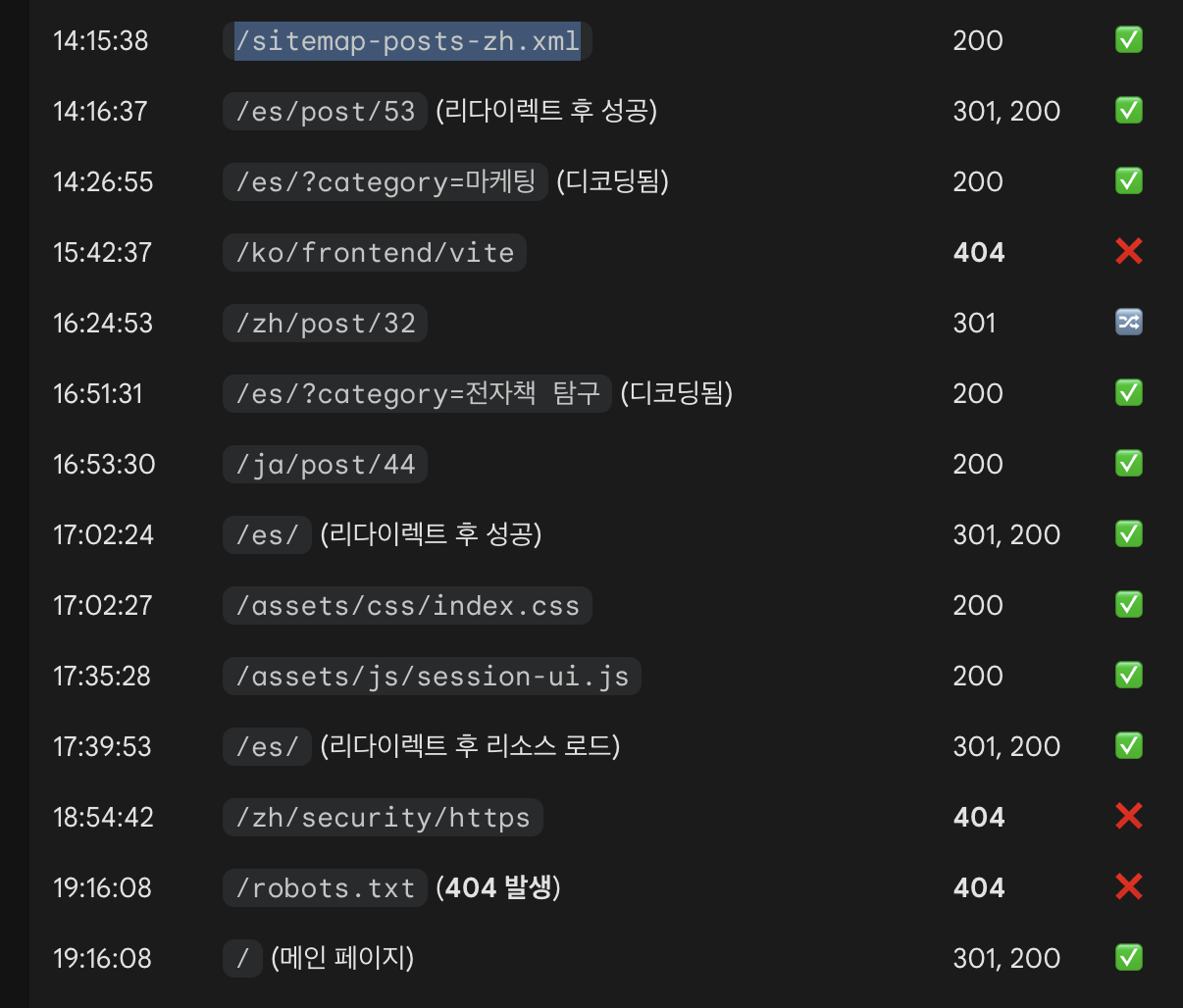 Googlebot requesting a sitemap XML file from access.log.1
Googlebot requesting a sitemap XML file from access.log.1
It requested one of the XML files from my sitemap—the one containing the post list for a specific language.
This means that even though Google doesn’t check the sitemap constantly, it does occasionally use it to discover whether new posts exist.
In reality, recent posts aren't crawled "in order from oldest to newest." Instead, crawling spreads out slowly from whatever link Googlebot *happens* to touch first—completely by chance.
I usually post in six languages, and among my latest posts, Googlebot had only crawled certain languages for certain posts. It’ll probably crawl the rest little by little. Once a post is crawled and analyzed, it’ll get indexed unless there’s an issue— and then it will finally show up in search.
I theoretically *knew* all of this, but actually seeing it with my own eyes made me ridiculously excited. So this is how it works...