我怎么之前没有想到这个?
很多人都会困惑:“为什么我发了博客文章却迟迟没有被索引?” 我也一样。 我以为 Google 完全无视了我的博客,感觉自己在广袤的网络世界里孤军奋战。
后来学习了一下才发现,爬取(Crawling) 其实就是 Googlebot 向我的网站发送请求, 而这些请求都会以 日志(log) 的形式保存在服务器里。 日志里面包含所有信息:请求时间、以及网站如何回应等内容。
那就开始吧。
如何确认 Googlebot 是否访问过我的网站
我使用的操作系统是 Ubuntu,网站服务器是 Nginx。 其他常见的 Web 服务器还有 Apache、Caddy 等。
在服务器终端输入以下命令,就能查看 Googlebot 的访问记录:
sudo grep -i "Googlebot" /var/log/nginx/access.log
这样会出现一大堆日志,太难读了,所以我全部复制后让 Gemini 帮我整理一下……
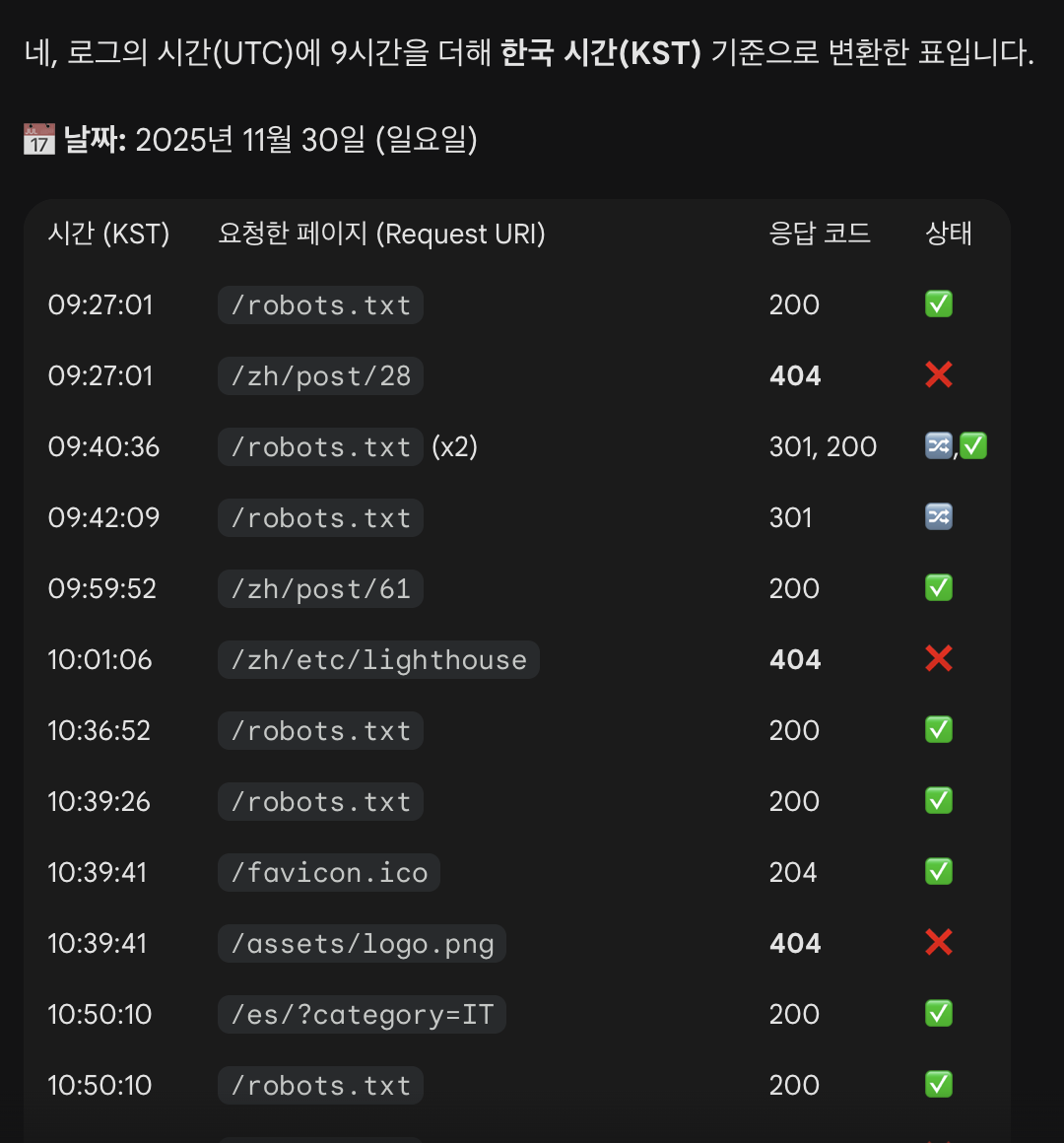 让 Gemini 汇总的 Googlebot 访问日志画面
让 Gemini 汇总的 Googlebot 访问日志画面
我原以为 Googlebot 根本不会访问我的网站, 但实际上它一直都在、持续不断地来访,甚至就在我查看日志的那一刻之前还来过。 Googlebot 真的一直在出入我的网站。
Googlebot 经常查看的页面
robots.txt
访问次数最多的页面是 robots.txt。 因为它决定了哪些页面不能被爬取,所以 Googlebot 会频繁检查。
以前发布的文章与资源
其次就是之前已经被收录过的页面。 其中很多页面现在已经被我删除了,所以服务器返回 404。 Googlebot 因为之前知道这些页面存在,所以会定期重新访问。
最新发布的文章
那么 Google 还不知道存在的最新文章呢? 查看昨天的日志,用下面这个命令:
sudo grep -i "Googlebot" /var/log/nginx/access.log.1就会看到类似这样的记录:
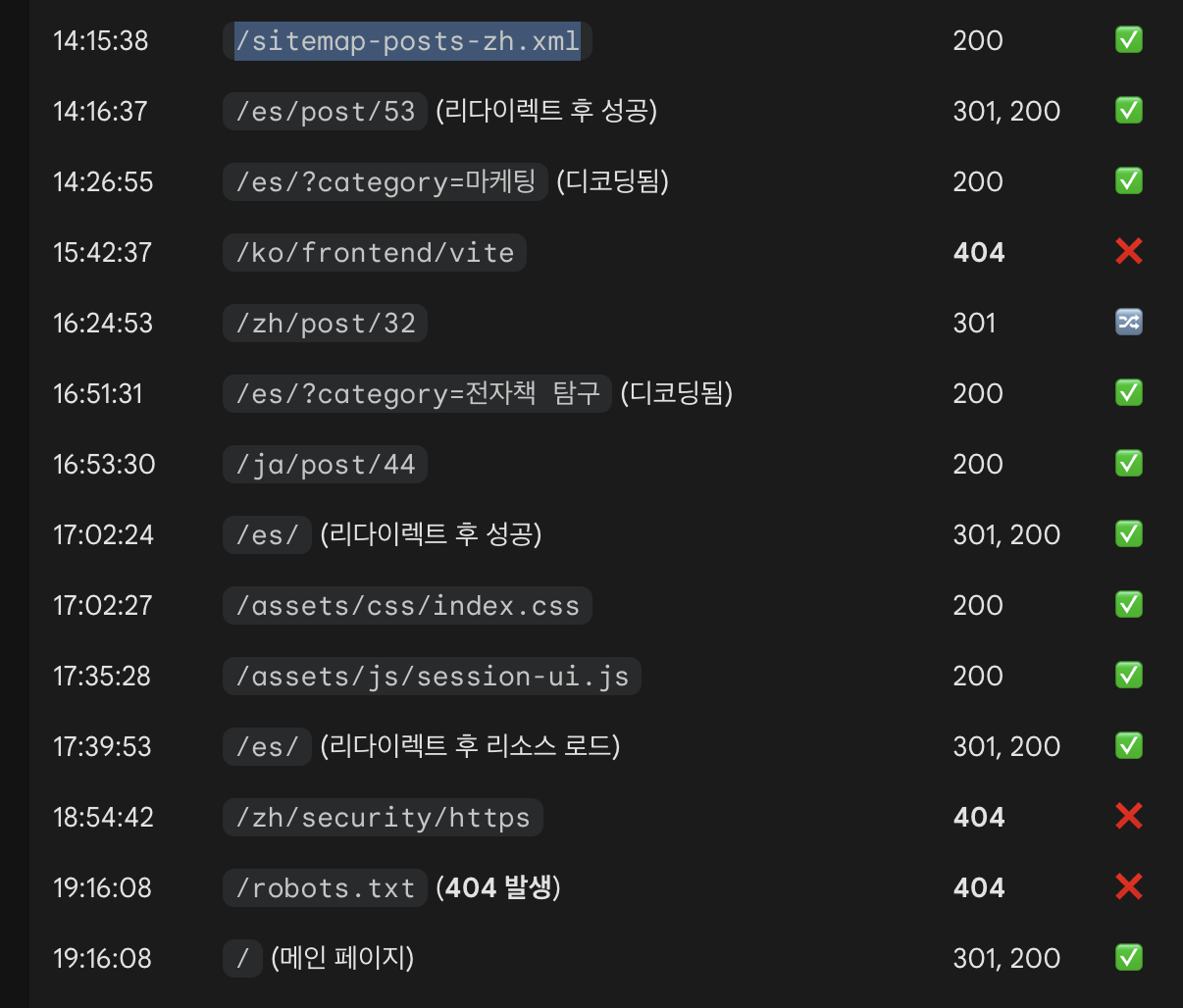 Googlebot 在 access.log.1 中请求 sitemap XML 的记录
Googlebot 在 access.log.1 中请求 sitemap XML 的记录
Googlebot 请求了 sitemap 中的一个 XML 文件,那里面包含某个语言版本的文章列表。
也就是说,虽然 Google 并不会一直查看 sitemap,但它会偶尔利用 sitemap 来判断是否出现了新内容。
实际上,最新文章并不是按“从旧到新、顺序严格地”爬取的。 Googlebot 会从某个“偶然碰到的链接”开始,慢慢往外扩散式地爬取。
我平时会把文章翻译成六种语言发布,而在最新的文章中,Googlebot 目前只爬取了其中某些语言版本。 其他的应该会在之后陆续爬取。 一旦文章被爬取并分析,只要没有问题,就会被索引,然后就能出现在搜索结果里。
这些东西我虽然理论上都懂,但真的亲眼看到日志时, 那种兴奋感完全不一样。 原来,是这样运作的啊……