なんで今まで気づかなかったんだろう?
多くの人が「ブログを公開したのに、なぜインデックスされないの?」と悩む。 ぼくも同じだった。Google が自分のブログを完全に無視しているように感じて、 広いウェブの世界でひとりぼっちで戦っているような気がしていた。
でも勉強していくうちに気づいた。クロールというのはつまり、 Googlebot がページを取得するためにリクエストを送ってくることで、 そのリクエストは全部 ログ としてサーバーに残る。 そこにはリクエストの日時や、サーバーがどう応答したかまで全部記録されている。
よし、行ってみよう。
Googlebot が自分のサイトに来ているか確認する方法
ぼくは OS に Ubuntu を、 Web サーバーには Nginx を使っている。 他にも Apache や Caddy など有名な Web サーバーがある。
Googlebot のアクセス記録を見るには、サーバーのターミナルで次のコマンドを入力する:
sudo grep -i "Googlebot" /var/log/nginx/access.log
すると大量のログが出てくる。読みづらいので全部コピーして Gemini にまとめてもらうと……
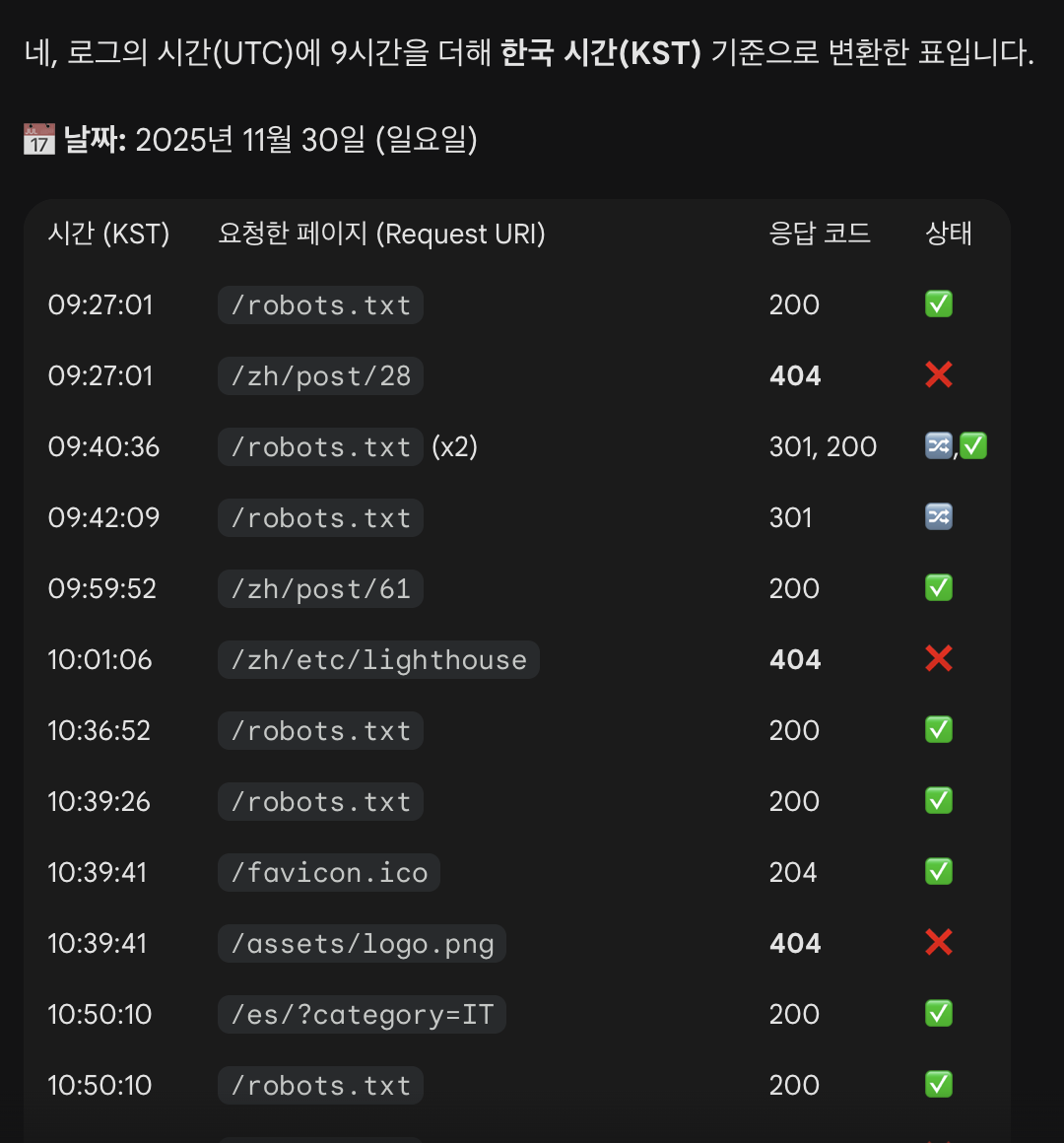 Googlebot のアクセスログを Gemini に要約してもらった画面
Googlebot のアクセスログを Gemini に要約してもらった画面
ぼくは Googlebot がまったく来ていないと思い込んでいた。 でも実際には、いつも・ずっと・ログを確認する直前まで来ていた。 Googlebot はずっと出入りしていたのだ。
Googlebot が頻繁にチェックしているページ
robots.txt
一番アクセスが多かったのは robots.txt。 どのページをクロールしてはいけないかを示す重要なファイルなので、頻繁に確認される。
過去に投稿した記事やリソース
次に多かったのは以前インデックスされたページ。 その中にはもう削除してしまったページも多いので、サーバーは 404 を返していた。 Googlebot は一度知った URL を定期的に再チェックするらしい。
最新の記事
では、Google がまだ存在を知らない最新記事は……? 昨日のログを次のコマンドで確認してみると:
sudo grep -i "Googlebot" /var/log/nginx/access.log.1こんな記録が見つかった:
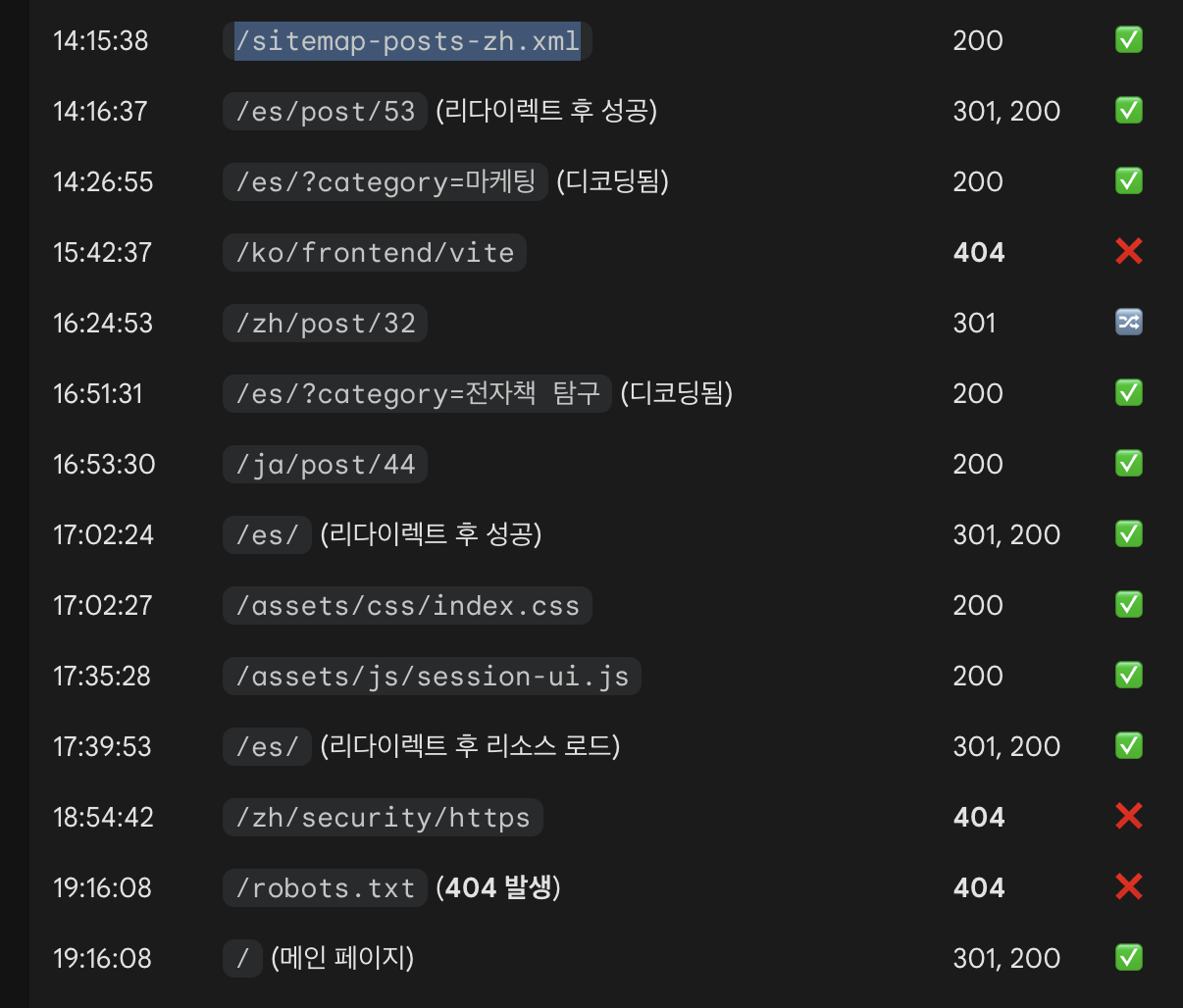 Googlebot が sitemap の XML をリクエストしたログ
Googlebot が sitemap の XML をリクエストしたログ
これは sitemap にある特定言語版の記事リストの XML を Googlebot が取得したという記録だった。
つまり、Google は sitemap を「常に」参照しているわけではないが、 ときどき sitemap を使って新しい記事があるかどうかを確認している。
実際には、最新の記事だからといって 「古い順に丁寧にクロールされる」わけではない。 Googlebot がたまたま辿りついたリンクから、少しずつ広がるようにクロールされていく。
ぼくは普段記事を6言語で公開しているけど、最新の記事の中でも、 Googlebot がクロールしたのは特定の言語バージョンだけだった。 ほかの言語版もそのうち少しずつクロールされるはず。 一度クロールされて問題がなければインデックスされて、検索結果にも表示されるようになる。
理論では知っていたけど、実際に自分の目でログを見るとめちゃくちゃワクワクした。 こういう仕組みなんだなぁ……