我最近的 Google 收录趋势
我把最近文章的收录情况简单做成了一个表格。
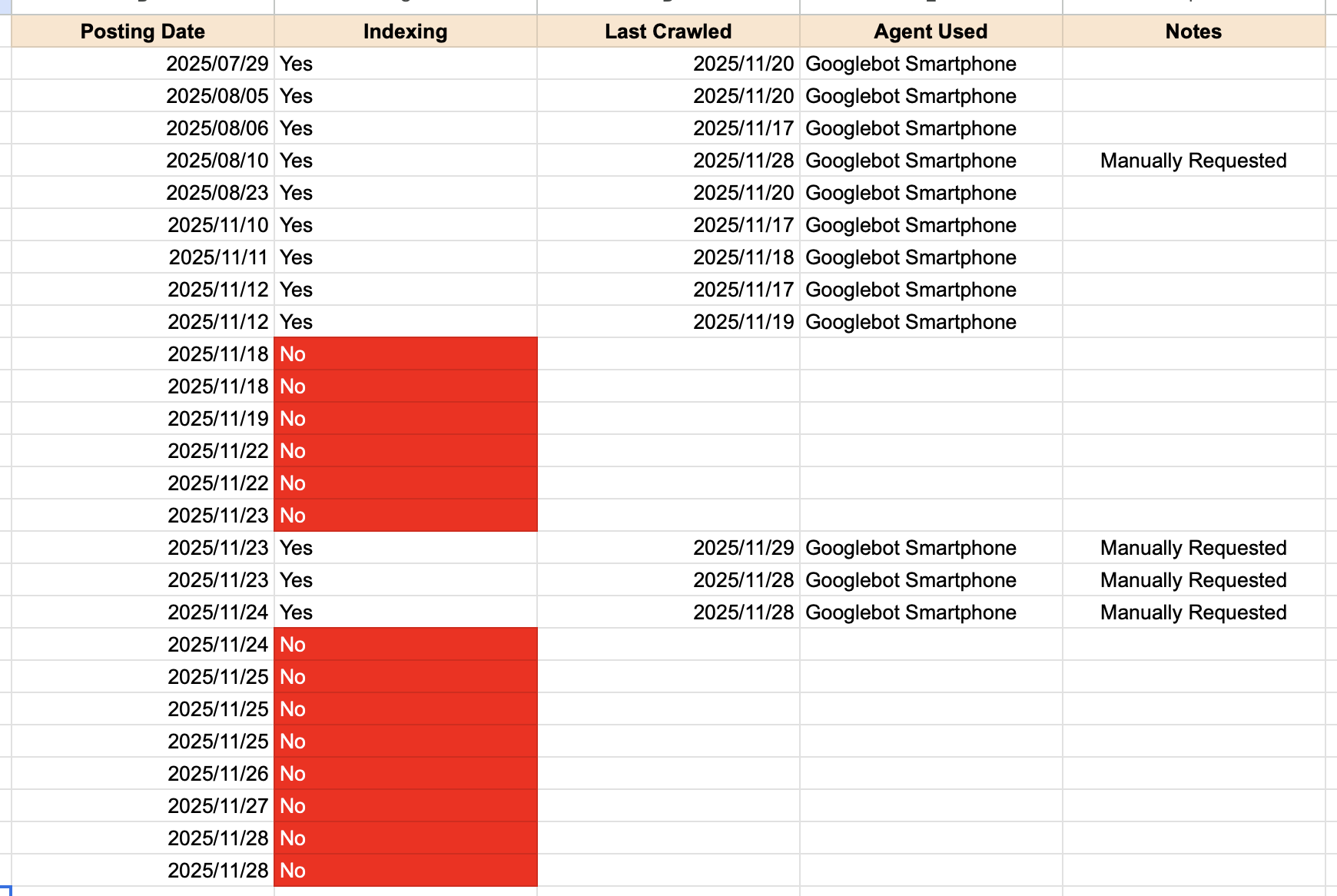
▲ 最近发布文章的收录情况表
- Posting Date:我发布文章的日期
- Indexing:是否已被收录
- Last Crawled:Google 最后一次抓取的时间
- Agent Used:抓取使用的 Googlebot 类型
- Manually Requested:是否为我手动提交
这里的“Agent”指的是Googlebot(爬虫)的类别,包括“Googlebot 智能手机”和“Googlebot 桌面版”。一般情况下,默认使用的是Googlebot 智能手机,也就是以移动端环境进行抓取。
通过 Search Console 手动提交 URL,通常能很快触发收录。但手动提交每天是有限额的。要判断某个页面是否“因我手动提交而被收录”,可以看这里:
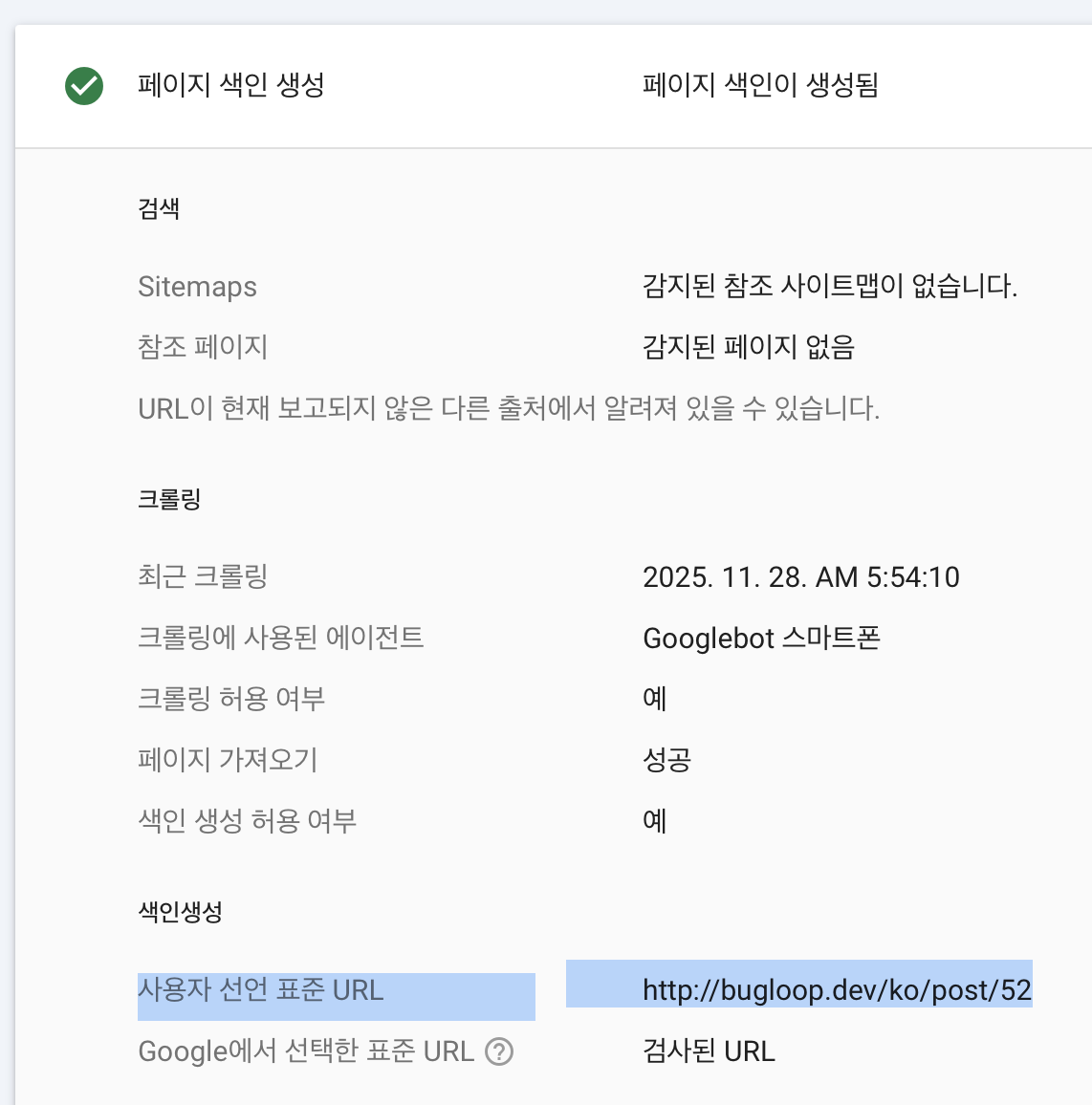
▲ 是否为“手动提交收录请求”的判断界面
如果在“用户声明的规范 URL”中出现了该文章的 URL,那就说明这是我手动提交的收录请求。如果没有出现,则表示 Google 自己抓取并收录了。
抓取(Crawling)指的是 Googlebot 来访问页面;收录(Indexing)是指 Google 对页面进行分析并写入自己的数据库。没有抓取就不可能有收录,而没有收录当然也无法出现在搜索结果中。
抓取预算(Crawl Budget)
在迷茫之前,我们先冷静理一理。深呼吸……
Googlebot 其实有一个概念叫抓取预算。抓取网页对 Google 来说都是成本,要花时间、资源和能耗(没想到有一天我也会替机器人着想…)。所以它不可能对所有网站无差别地无限抓取,而是会根据网站的权威度分配预算。
什么?大而可信的网站?那当然要给高预算!
抓取预算和抓取频率不是一个概念,但预算越高,Google 通常抓得越频繁——因为它信任这个网站,并愿意投入更多资源。这也解释了为什么 Reddit、DCInside 这种大型社区的帖子能几乎秒级被抓取。
但我呢?我的这个刚建好的小型个人博客?抓取预算一定是非常、非常、非常有限的。如果在这个有限预算里,Google 遇到很多 404 页面,那它本来能抓取的其他页面机会就被浪费了。更严重的是:500 / 502 / 503 等服务器错误会进一步拉低抓取预算。
开发过程中我也确实制造过这种服务器错误……某次还生成过大量空页面 URL。这样的情况当然都有可能让 Google 降低分配给我的预算。而且如果我很久不更新文章,Googlebot 也会来得更少——毕竟网站没什么变化,它也没必要常来。
暂时……我先不再手动提交收录,等几天再观察抓取趋势。