Tendances récentes de l’indexation Google
J’ai résumé dans un tableau l’état d’indexation de mes derniers articles.
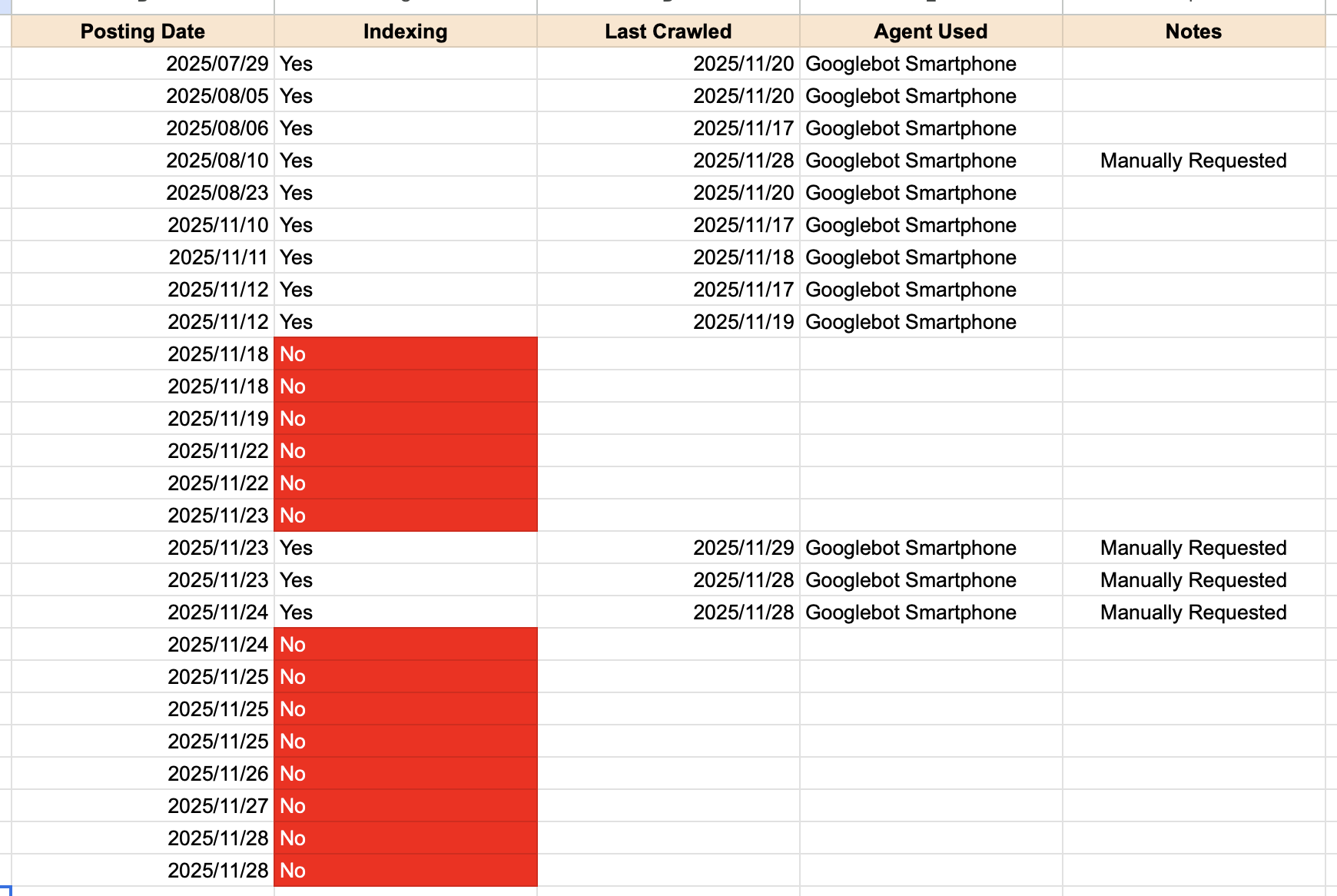
▲ Tableau de l’état d’indexation de mes récents posts
- Posting Date : la date à laquelle j’ai publié l’article
- Indexing : l’article a-t-il été indexé ?
- Last Crawled : la dernière date de crawl par Google
- Agent Used : l’agent Googlebot utilisé pour le crawl
- Manually Requested : soumission manuelle via Search Console
Ici, le terme agent désigne le type de Googlebot utilisé : “Googlebot Smartphone” et “Googlebot Desktop”. L’agent par défaut est généralement Googlebot Smartphone, qui simule l’environnement mobile.
Quand on soumet une URL directement via la Search Console, son indexation se fait assez rapidement. Mais il existe une limite quotidienne de soumissions manuelles. Pour savoir si une page a été indexée suite à ma demande manuelle, il suffit de vérifier ici :
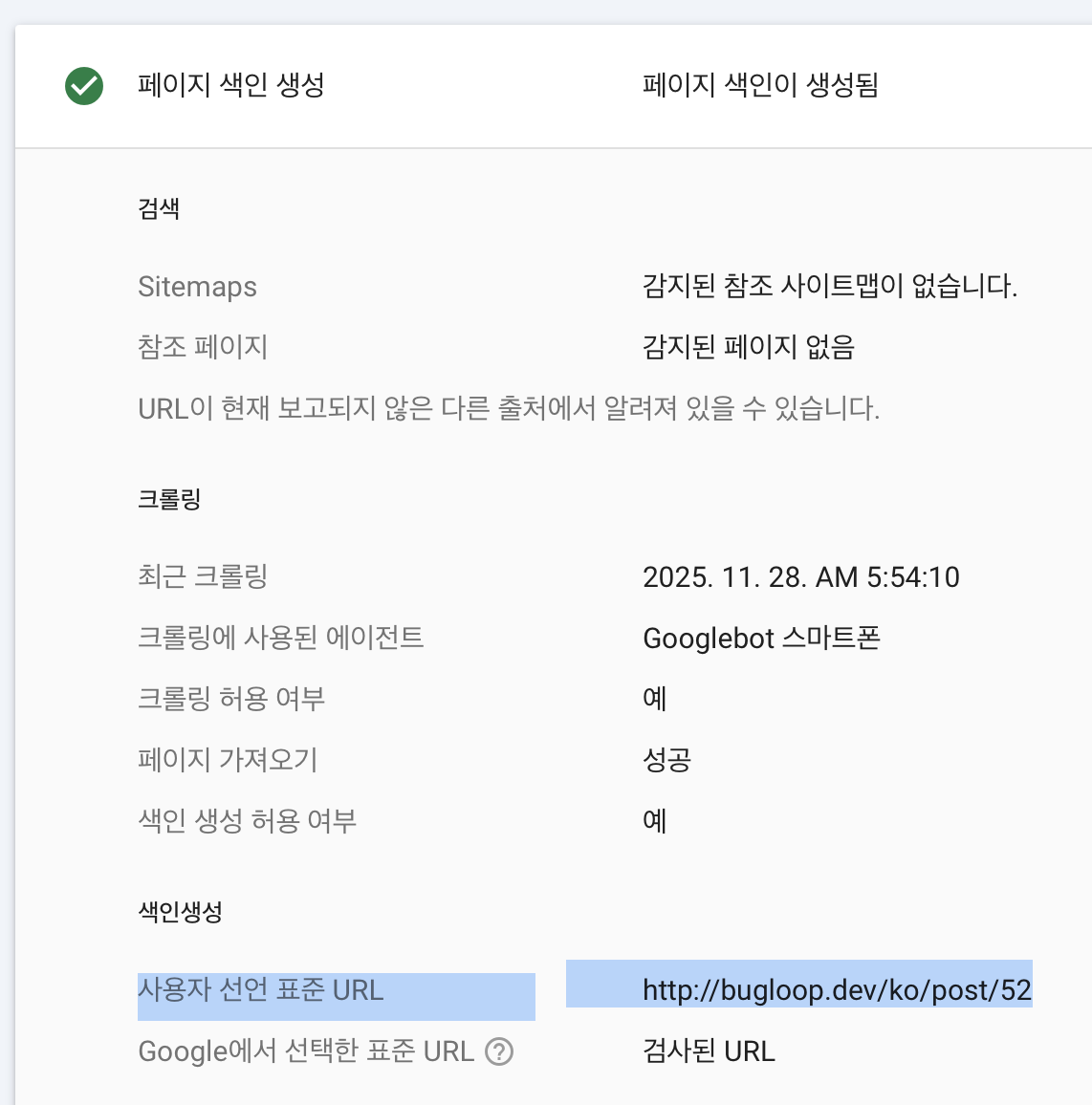
▲ Écran indiquant la présence d'une soumission manuelle
Si l’URL apparaît dans le champ URL canonique déclarée par l’utilisateur, cela signifie que j’ai moi-même demandé l’indexation. S’il n’y a rien, c’est que Google est venu crawler la page de son propre chef.
Le crawl signifie simplement que Googlebot a consulté la page. L’indexation, elle, correspond au moment où Google analyse cette page et l’ajoute à sa base de données. Sans crawl, il ne peut évidemment pas y avoir d’indexation, et sans indexation, impossible d’apparaître dans les résultats de recherche.
Le budget de crawl (Crawl Budget)
Avant de paniquer, analysons calmement tout ça. Inspiration…
Googlebot dispose d’un concept appelé budget de crawl. Le crawl a un coût : du temps, des ressources, de l’énergie côté Google. Google ne peut pas crawler tout le web sans limite, donc il alloue un budget différent selon l’autorité perçue du site.
Ah ! Un grand site fiable ? Alors on augmente généreusement son budget de crawl.
Le budget de crawl et la fréquence de crawl ne sont pas exactement la même chose, mais un budget élevé mène en général à des visites bien plus fréquentes. Google fait confiance au site, il y consacre plus de ressources — ce qui explique pourquoi Reddit, DCInside ou les grandes communautés sont crawlé•es presque instantanément après la publication d’un post.
Mais moi, avec mon tout petit blog fraîchement développé ? Le budget de crawl doit être… minuscule. Et si, dans ce budget déjà limité, Google tombe souvent sur des erreurs 404, cela “gaspille” son budget. Moins il peut explorer d’autres pages. Les erreurs serveur 500 / 502 / 503, elles, font encore plus chuter ce budget.
Pendant le développement, j’ai évidemment provoqué quelques erreurs serveur… Et j’ai même généré un grand nombre d’URL vides à un moment donné. Tout ça peut amener Google à revoir mon budget à la baisse. Si je publie peu, Googlebot viendra aussi moins souvent — pourquoi se déplacer si le site ne bouge pas ?
Pour l’instant… je vais attendre quelques jours sans soumissions manuelles. Ensuite, j’observerai à nouveau les tendances.