Recent Indexing Patterns on My Blog
I organized the indexing status of my recent posts into a simple table.
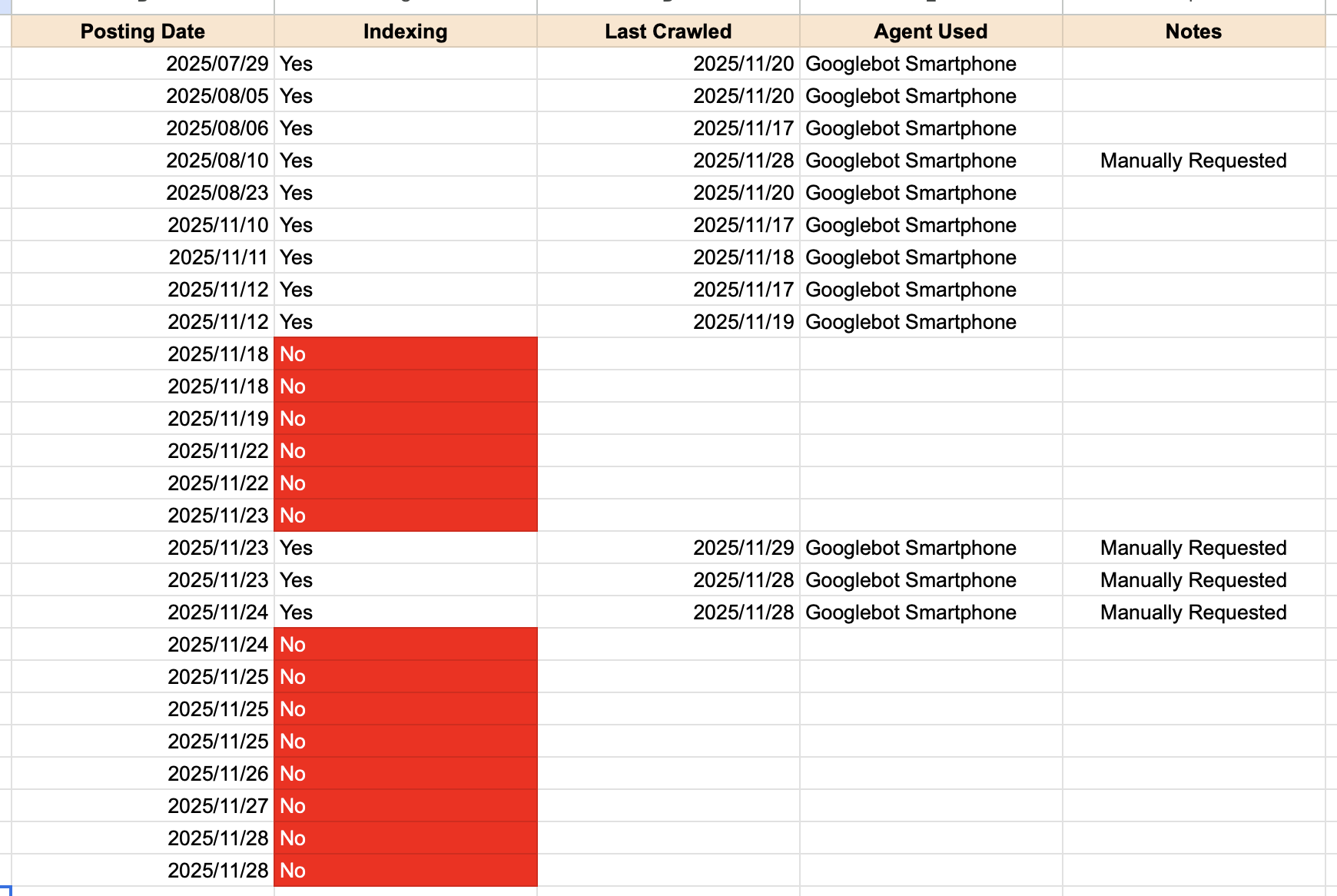
▲ Indexing status of my recent posts
- Posting Date: The date I published the post
- Indexing: Whether the page is indexed or not
- Last Crawled: The date Google last crawled that URL
- Agent Used: The Googlebot variant used for crawling
- Manually Requested: Whether I manually submitted an indexing request
The agent here refers to the type of Googlebot that performed the crawl. There are two main variants: “Googlebot Smartphone” and “Googlebot Desktop.” Googlebot Smartphone is the default, meaning Google crawls my pages as if it were visiting from a mobile device.
If I manually submit a URL in Google Search Console, indexing usually happens fairly quickly. But there is a daily limit for these manual requests. You can check whether a page was indexed because I manually submitted it by looking here:
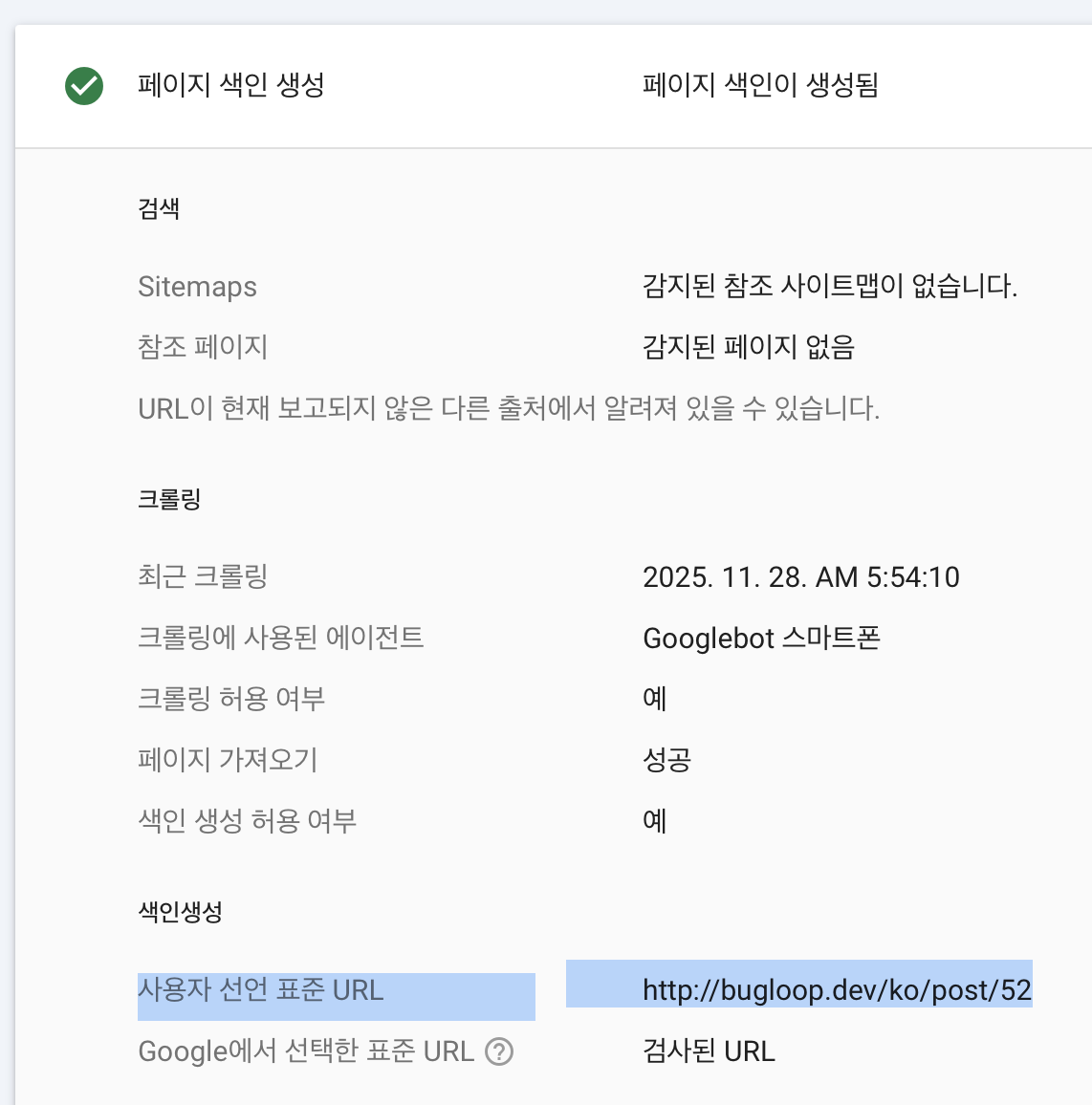
▲ How to check if the page was manually submitted for indexing
If the User-declared canonical field shows the exact URL, that means I manually submitted the indexing request. If it’s empty, Google crawled the page on its own.
Crawling simply means Googlebot accessed the page. Indexing is when Google analyzes that crawled document and stores it in its database. So if Googlebot never crawled the page, indexing obviously cannot happen. And if a page isn’t indexed, it cannot appear in search results at all.
Crawl Budget
Before getting confused, let’s break things down properly. Deep breath…
Googlebot operates under a concept called the crawl budget. Crawling the web costs time and server resources, even for Google. (I can’t believe I’m now considering the robot’s perspective!) Since Google can’t crawl every page endlessly, it allocates crawl budget based on how authoritative and trustworthy a site seems.
Oh? A large, highly trusted site? → Higher crawl budget!
The crawl budget isn’t the same as crawling frequency, but the two are loosely correlated. A higher budget often means more frequent crawling. Google trusts that site more and is willing to spend more resources on it. That’s why platforms like Reddit or DCInside get crawled instantly—even low-effort posts appear in search results almost immediately. Google basically sits next to those sites waiting for new content.
But my blog is tiny compared to those giants—just a small personal project I recently finished building. My crawl budget is probably extremely, extremely low. So Googlebot is basically stingy with me. If my site returns many 404 errors, the resources Google spends running into those errors reduce the time it can spend crawling actual content. Server errors like 500/502/503 reduce the crawl budget even more.
I definitely had a few server errors while developing the site… maybe that affected it? Or maybe because I once accidentally generated a large number of empty URLs? Honestly, there were plenty of chances for Google to lower my crawl budget. And if I stop posting for long periods, Googlebot visits even less frequently—why waste time checking a site that rarely updates?
For now… I’ll try not submitting anything manually and just wait a few more days. Then I can look at the pattern again.